RC 20874 (log #92282) 7MAY97
Computer Science/Mathematics 16 pages
Research Report
Lexical Navigation:
Visually Prompted Query Expansion and Refinement
James W. Cooper and Roy J. Byrd
IBM Research Division
T.J. Watson Research Center
P.O. Box 218
Yorktown Heights, NY 10598
LIMITED DISTRIBUTION NOTICE
This report has been submitted for publication outside of IBM and will probably be copyrighted if accepted for publication. It has been issued as a Research Report for early dissemination of its contents. In view of the transfer of copyright to the outside publisher, its distribution outside of IBM prior to publication should be limited to peer communications and specific requests. After outside publication, requests should be filled only by reprints or legally obtained copies of the article (e.g., payment of royalties).
![]() Research Division
Research Division
Almaden v T.J. Watson v Tokyo v Zurich v Austin
Abstract
We have designed a document search and retrieval system, termed Lexical Navigation, which provides an interface allowing a user to expand or refine a query based on the actual content of the collection. In this work we have designed a client-server system written in Java to allow users to issue queries, have additional terms suggested to them, explore lexical relationships, and view documents based on keywords they contain. Lexical networks containing domain-specific vocabularies and relationships are automatically extracted from the collection and play an important role in this navigation process. The Lexical Navigation methodology constitutes a powerful set of tools for searching large text collections.
1. Introduction
Search of document databases, as supported for example by commercial services such as Dialog, Lexis-Nexis, and Derwent or by World-Wide Web search engines such as Altavista, Lycos, and Infoseek, is not usually a one-step process. Rather, successful searches, in the overwhelming majority of cases, involves user iteration over a sequence of operations. Typical operations include the ones listed in Table 1.
Users can have various goals when performing a search. Among the possible goals are:
find an answer to a specific question
find a single quotation/document which exemplifies a concept or relationship
find multiple/all documents which discuss a concept or relationship
explore the contents of the database starting from some concept.
As a search session proceeds, the user’s goals may change. For example, upon obtaining a surprising answer to her specific question, a user might next enter exploratory mode in order to understand the answer and finally move to quotation mode in order to find the best way to explain the answer to her students and colleagues.
Table 1. Operations performed during document database search |
|
| formulate information requirement or need | |
| select a document collection ("file", "category", "source", etc.) | |
| * | map information requirement to query terms |
| * | enter a query |
| * | expand query with additional query terms |
| * | process query |
| read hitlist of resulting documents | |
| * | match hitlist items to query terms |
| read summaries of hitlist documents | |
| retrieve and read hitlist documents | |
| * | find relevant query terms in documents [highlight/KWIC] |
| find relevant domain concepts in documents [highlight/KWIC] | |
| * | map new domain concepts to additional query terms |
The starred items in Table 1 illustrate the fact that queries, which express the user’s information requirements, are central to most search process operations. Users focus their attention and energy on the creation of queries which adequately express their requirements and which will effectively retrieve documents that meet their goals. In practice, this means that users work very hard to come up with query terms that express the concepts they want to find, exemplify, or explore.
During most search processes, a query will be written, expanded, issued, matched to documents, re-formulated, and re-issued many times. Successful document retrieval systems must therefore provide not only good document-management functions but also good query-management functions. Included in the query-management functions must be a good set of facilities for expanding and refining queries, for keeping track of query modifications, and for helping the user understand the effect these modifications have on queries' effectiveness at retrieving documents which meet the information requirement.
This paper describes an approach to query expansion and query refinement that employs active user interface objects to prompt users with query terms that are likely to be productive. A central role in our approach is played by collection-specific vocabularies which are used as the source of the query terms with which users are prompted.
Section 2 of the paper describes our approach to query modification and contrasts it with previous methods described in the literature. Section 3 describes the user interface architecture that provides access to the system's facilities, with special attention being paid to facilities for query modification. Section 4 gives a brief overview of the text analysis mechanisms used to derive the collection-specific vocabularies. Finally, section 5 summarizes the current status of the work and describes future activities based on the ideas presented here.
2. An Approach to Query Refinement
The problem of guiding a user to formulate queries to obtain useful results from large data collections has been widely studied. Local feedback was utilized by Buckley [Buckley, et al., 1996] and Xu and Croft, [Xu & Croft, 1996] who also utilized local context analysis using the most frequent 50 terms and 10 two-word phrases from the top ranked documents to perform query expansion. [Schatz. et al. 1996] describe a multi-window interface that offers users access to a variety of published thesauruses and computed term co-occurrence data.
This problem becomes more involved when we include the difficulty of providing a simple user interface suitable for infrequent use by non-technical users. Envision [Nowell, et al., 1996] is one such interface although it was designed primarily for use in searching technical journal collections. Another approach, termed Scatter/Gather [Hearst & Pedersen, 1996], emphasized clustering of similar documents into several subgroups in response to the initial query. Fireworks [Hendry & Harper, 1996] presents a unique scattered screen environment called SketchTrieve which allows manipulation of queries, documents, authors and results as separate, moveable windows.
When translating an information requirement into a query for a document retrieval system, a user must convert concepts involved in his requirement into query terms which will match terms found in documents in the data base. Such a user faces "the vocabulary problem" described in [Furnas, et al. 1987]. One aspect of this problem is that a word may not be precise enough to ensure a focused response. For example, a query containing the term "fruit" will not be as helpful as one containing, "pear," "nectarine," or "raisin," assuming that the latter concepts are part of the information requirement. A related aspect of the vocabulary problem concerns ambiguous words. An otherwise unconstrained query containing the query term "nut" is likely to return documents related to hardware, seeds, and eccentric people, assuming such documents are in the database. Finally, the vocabulary problem also encompasses the fact that (according to [Voorhees, 1994] and [Bates, 1996]) large full-text databases contain many different expressions for the same concept.
In the information retrieval literature, solutions to the various aspects of the vocabulary problem are usually described and evaluated as methods for improving an IR system's recall and precision. It is generally believed that recall can be enhanced by including additional terms that are likely to occur with -- or to mean the same thing as -- terms already in the query. The corresponding belief about precision is that is that ambiguous query terms can be disambiguated by also including in the query terms which are likely to occur with only one sense of the ambiguous term. For example, if the query about "nut" also contained "bolt," then retrieved documents will be more likely to involve hardware than seeds or eccentrics.
Various manual and automatic techniques for enhancing queries under these assumptions are described in[Harman, 1992], [Voorhees, 1994)], [Schatz et al., 1996] and [Xu and Croft, 1996]. The techniques can be categorized as either (1) "query expansion" - adding query terms related to information requirement concepts and obtained from thesauruses or co-occurrence lists or (2) "relevance feedback" - adding query terms obtained from documents known to be relevant to the information requirement. Although some successes have been reported with automatic techniques (see [Xu and Croft, 1996]), they have generally not been spectacular for several reasons.
First, reliable technology for automatically disambiguating query terms is not available. Lesk [Lesk, 1986] and subsequent work based on it has shown how to use definitions in machine-readable dictionaries to disambiguate some common words. For example, we can determine whether the word "cone" occurring in a sentence is an "ice cream cone" or a "pine cone" by choosing the one whose dictionary definition has the largest overlap with words in the sentence. However, those techniques will not work for queries containing proper names or technical terms which are not present in dictionaries. Furthermore, most (initial) document queries consist of only a few words and are, hence, not suitable for use with the word overlap techniques which require a significant amount of word context. Even when they do work, these techniques do not provide an correct answer in a sufficient number of cases to be of much use for query expansion.
Another problem with automatic techniques which rely on pre-existing thesauruses is that they typically don’t contain the most useful types of information for query expansion. New names and technical terms appear faster than they can be captured in published works. Furthermore, such thesauruses often contain only synonym, hypernym, and hyponym relationships. Real relations among technical terms and names are much richer and query expansion methods that ignore them are at a disadvantage.
A final problem with automatic query expansion techniques is that they ignore perhaps the best sources of knowledge about what would be good terms to add to queries: the user and (except for relevance feedback techniques) the documents.
LexNav Operation
We address the above problems using a technique called "lexical navigation", which we developed for use in the user interface to the "LexNav" document query and retrieval system. In LexNav, we solve the vocabulary problem using methods which take advantage of all of the collection's documents and of the user's intuitions about concepts related to the ones in the information requirement. Before queries begin, we use a suite of text analysis tools called "Talent" to develop a vocabulary of the ordinary words, proper names, and technical terms by analyzing the entire collection. Additional Talent tools organize the vocabularies into an extensive set of relationships consisting of triples of
<vocabulary-item::relation::vocabulary-item>.
In these relationships, the "vocabulary-items" are used to represent the real-world concepts that they name. The "relations" give either the name or the strength of an association between the related concepts.
It has been pointed out in [Byrd, et al., 1995] that the largely multi-word items in Talent vocabularies can be highly effective at enhancing the precision of query processing. In terms of Lesk's example, the term "pine cone" is not ambiguous. Most modern search engines would zero in on documents containing this term, while de-emphasizing or excluding other mentions of "cone".
After they are extracted, the entire set of relationships for a collection is organized into a "lexical network," in which the vocabulary items are the nodes and the relations are the links. The lexical network is maintained on a server - usually the same server as the one on which the documents themselves and the search engine index are kept. LexNav server processes are used to match initial queries and query terms to nodes in the lexical network. The links are used for navigating to nodes of related vocabulary items, which are then returned to client LexNav processes for use in prompting the user during query modification.
A by-product of the derivation of lexical networks is another object called a "context thesaurus" which, given a probe consisting of a single word or an entire query, produces a ranked list of vocabulary items (i.e., nodes in the network) that are related to the probe. The context thesaurus is somewhat similar to (and was inspired by) the "phrase finder" procedures described in [Jing and Croft, 1994]. LexNav's context thesaurus server is also used to respond to a client request for query terms to be added to an initial query. Further, LexNav emphasizes the use of a graphical interface.
During a LexNav query session, the user has constant access to the lexical network and context thesaurus servers. At any point during the query process, lists of vocabulary items representing concepts related to the current query or document can be viewed. Users can expand the query with new query terms by simply clicking on desired vocabulary items. Furthermore, navigation through the context thesaurus and the lexical network themselves is also iterative: users may move from node to node with a simple point-and-click interface over a visual representation of the network's contents.
It is useful to consider the properties of the LexNav interface in the context of a set of design criteria developed in Spink(1994). That paper analyzes data obtained during a study of query development by users and human intermediaries (i.e., librarians). At issue are the roles and sources of "term relevance feedback" (TRF) in query expansion. Specifically, TRF refers to query modification using terms obtained from documents retrieved earlier in the query process. In fact, however, the paper also discusses terms that originate with users, intermediaries, and thesauruses.
Spink lists 4 findings concerning the terms in final successful queries:
TRF is the source of relatively few terms (as compared to the other sources - users, intermediaries, and thesauruses),
TRF terms are more successful (than those from the other sources) at finding relevant documents,
TRF terms chosen by intermediaries are more successful at finding relevant documents (than those chosen by users).
TRF terms come mostly from document titles and descriptors (rather than from abstracts or texts).
There is a challenge in findings 1 and 2: TRF terms are the most successful but least abundant query terms. LexNav can help users meet this challenge by showing them related terms from all text in the collection, not just from the titles and descriptors of a few documents seen on early hit lists (see finding 4). Relevant related vocabulary items are available in the context thesaurus and lexical network, which, in effect, offer predigested relevance feedback information for the entire document collection.
If we assume that the relative success of TRF terms selected by intermediaries (reported in finding 3) is due to the intermediaries' familiarity with the document collection, then we can argue that vocabulary items and relationships drawn from the database have the same advantage. In other words, these vocabulary items are guaranteed to exist in the document collection and, hence, to retrieve documents containing them. Thus, they represent LexNav’s analogue to the intermediary’s familiarity with the subject domain and its vocabulary.
3. Architecture of the Lexical Navigator Client
Based on the technology described above, we have developed the LexNav client user interface which illustrates the behavior and use of the context thesaurus and lexical network. Working with users and other IR experts in the group, we developed the LexNav interface, which supports most of the operations in Table 1. We felt it was important that the user interface look professional but simple, and that it run on common platforms like Windows as well as on some of our developers’ Unix workstations.
Accordingly, we developed the interface program in Java [Arnold & Gosling, 1996], and after some experimentation we decided that it should be presented as a Java applet in a Web browser rather than as a stand-alone application, thus making the entire search system available for testing by users on our company-wide intranet.
Java processes running as applets embedded in Web pages have significant security restrictions to prevent foreign applets downloaded with Web pages from doing mischief to the user’s computer system. However, such applets are still allowed to make TCP/IP socket connections back to the HTTP server machine and this provides the client-server communication pathway [Cooper, 1996].
The Java Server
The actual retrieval of information for queries is accomplished by sending the queries to a server process, also written in Java but running on an IBM RS-6000. This server process, in turn, calls any of a number of C programs which perform the queries of the various components of the LexNav system. Each instance of the server then provides a separate connection to the retrieval system and recognizes 6 commands which call programs based on arguments to these commands and receive data from these programs through standard-out. Then the server instance formats and returns these data to the query process on the client workstation.
The commands each server instance supports include
call the context thesaurus
call the relationships graph program
call the text search engine
fetch and format the document
identify each document’s keywords and mark them in a copy of the document
fetch the keyword-marked document
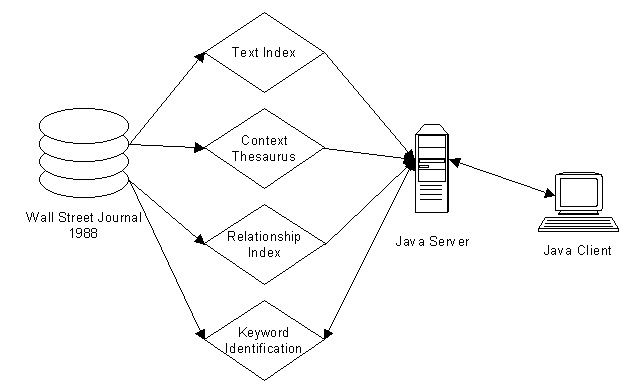
Figure 1: Lexical Navigation Client-Server System
The Lexical Navigator Client
Figure 2 shows the main Lexical Navigation interface. You can enter queries in the multi-line text box at the top and then either click on the query button directly to inspect document titles in the right hand list box, or you can click on the "related concepts" button, which calls the context thesaurus server process to return terms related to the query terms. In Figure 3, we show the context thesaurus keyword results of the query "airbus" on the 1988 Wall Street Journal collection [NIST, 1993]. Terms from the context thesaurus are computed to have at least a strong unidirectional relationship to the query terms.
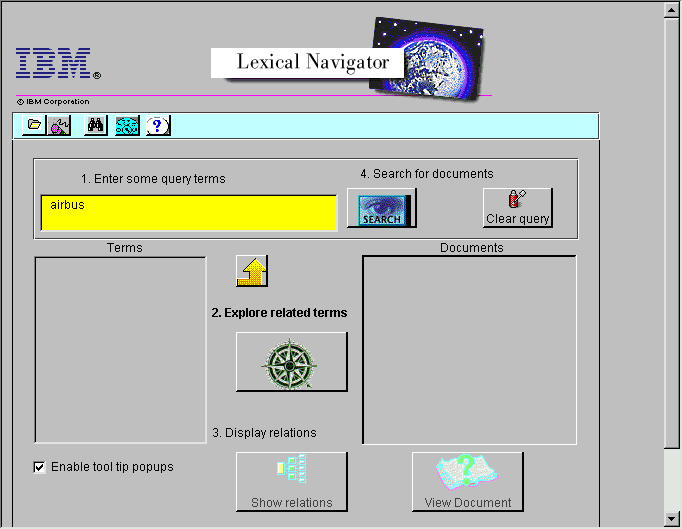
Figure 2: The Lexical Navigator interface
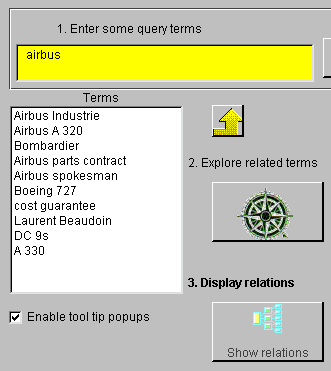
Figure 3. Context Thesaurus results of query "airbus."
Once LexNav has identified these additional terms, you can add any of them to the additional query, but can also investigate them further by querying what sort of relationships exist between these (sometimes surprising) terms and other terms you expect to find in this collection. In Figure 4a, we show these relationships for several of the query terms, which shows why some of the terms were found to be relevant. Two kinds of relationships are shown: named and unnamed relationships. Named relationships show the type of relation between the terms, while in the case of unnamed relationships, the strength of the relation is shown. In this display the relationship strength is represented by one, two or three asterisks. If the relationship is determined to be named, the name is shown in the middle column.
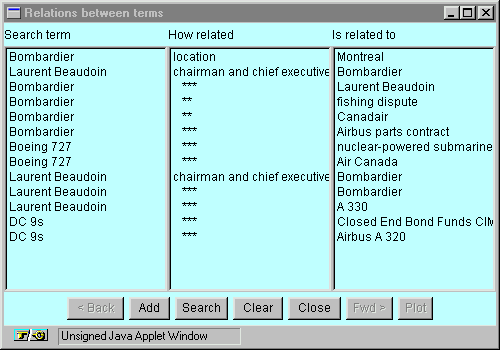
Figure 4a - Relationships between query terms and nearby terms
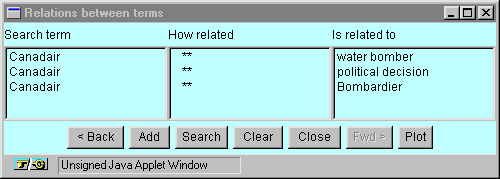
Figure 4b - Further relations of term "Canadair."
The interface allows you to add any marked term to the query at this point or to navigate further in relationship space by selecting one or more terms and clicking on the "Search" button. We see the results of further navigation in Figure 4b, where we have moved outward one relationship level to find terms related to the selected terms. Again, you can add these terms to the query or migrate further. In addition, you can view these relationships graphically by clicking on the "Plot" button, which produces the display shown in Figure 5.
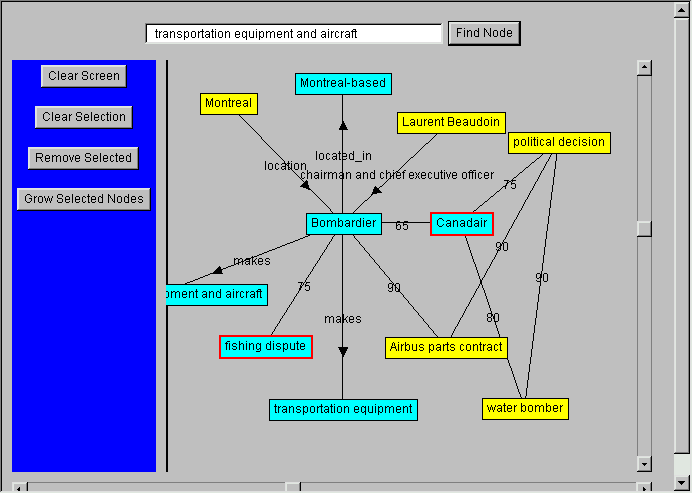
Figure 5 - Plot of term relations around "Bombardier" and "Canadair."
Terms in the lighter-colored boxes can be expanded further by double clicking on them to show additional terms, thus allowing the user to discover all of the relationships for each additional term. This represents an additional, powerful way of navigating through concept space: to discover distant, but significant relationships between terms.
The relationships between terms are also represented in this plot, with either the relationship name or the strength of the relationship shown along the line. Should the plot become too cluttered, you can drag any box to a new position. You can also regroup terms into a single box or erase them completely.
Searching for Documents
We have now narrowed our original query using the context thesaurus and terms from the relationships index and will use this refined query to search the collection. The result of this search is shown in Figure 6, where right-clicking on any document title in the list will produce a list of the search terms contained in that document.
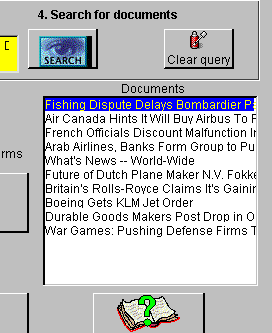
Figure 6 - Results of search query
Clicking on the "View" button produces the display in Figure 7. This Web page is constructed dynamically by the server, and consists of a frame where the left third is a Java applet and the right two thirds is a HTML-wrapped version of the Tipster1 format data, with the search terms converted to boldface.
The list box at the top left is a keyword-in-context display made from a custom Java control. Clicking on any line in this KWIC display moves the document in the right frame to that point. The list box in the lower left contains a list of keywords discovered in that document. Finally, clicking on the "Show Keywords" button at the lower left displays the document with the discovered keywords highlighted.
In summary, the interface provides a simple way to access a number of complex relationships and elicit responses from users based on their original vague queries to help them focus their query on specific areas within large collections.
User Evaluations of the Interface
As part of the evaluation of Lexical Navigation we enlisted the help of the User Interface research group at IBM. We also made an informal study of the reactions of a number of lab visitors from both technical and non-technical backgrounds. The overall informal evaluation of the non-technical visitors was very favorable, although most needed some explanation of the concept of related terms.
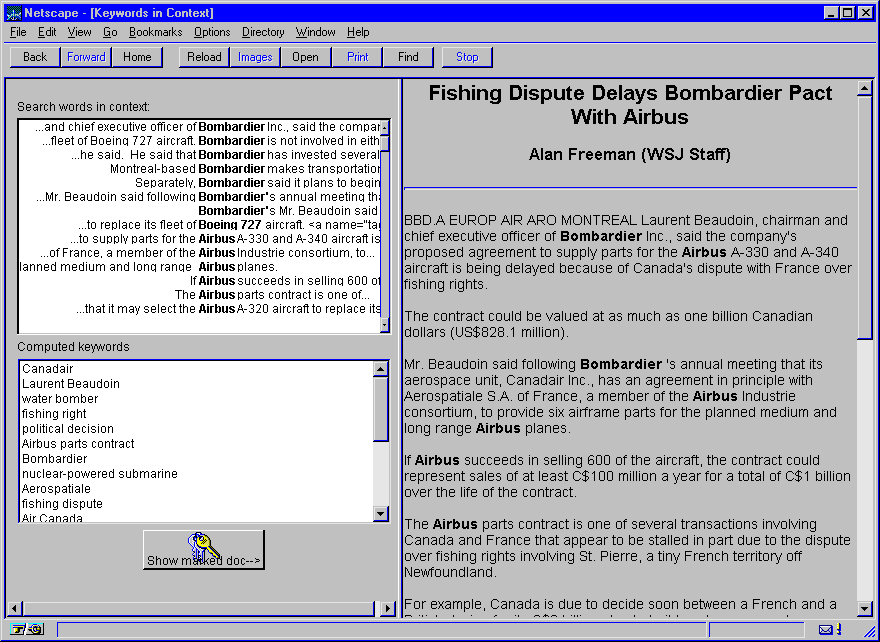
Figure 7 - Keyword in context, discovered keywords and highlighted search terms
The User Interface research group provided a number of practical suggestions for improvements as well as noting some features that were difficult to implement with the visual controls provided in Java 1.0. The suggestions included providing navigational push buttons to move from one document to another without going back to the main document list, and providing a progress indicator while the client is waiting for a server process. Since it is not easy to predict how long a server process will take, we have elected to provide an animated icon to simulate "work" while the server computes the terms or documents requested.
Another valuable suggestion was presenting keywords-in-context in the same order they were entered in the original query, on the assumption that the user entered them with the most important keywords first.
Other wishes included solving technical problems related to applets running on separate Web pages. For example, the key word list that is generated in an applet on the second web page (Figure 7) can only communicate back to the search term list through a server command.
We also have begun to investigate some alternate interfaces. For example, we have recast the plot of the lexical network to give it more visual appeal and perhaps keep users from becoming confused when a number of terms appear at once. This revision is shown in Figure 8.
We have also investigated using a tabbed notebook style interface and are currently investigating the simplest possible "one button" interface, designed primarily for executives.
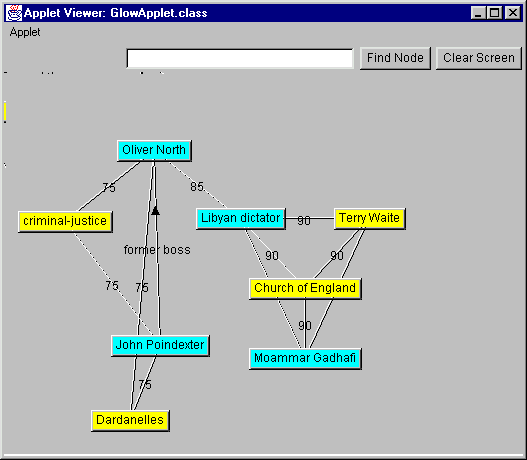
Figure 8 - A three-dimensional style lexical network plot.
4. Lexical Navigation Server Processes
The LexNav server processes consist of two layers. The lower layer includes those processes which operate on the document collections at "indexing" time and create the vocabularies, context thesauruses, and lexical networks. These processes are built using the extraction tools in Talent ("Text Analysis and Language Engineering Tools"). The upper layer consists of server processes in LexNav which allow the client to retrieve information in the vocabularies, context thesauruses, and lexical networks. These are mostly built with Talent access functions.
The upper layer server processes are constructed as follows: A single Java server process runs as a TCP/IP socket server on an AIX machine, blocking until a connection is initiated through a socket request from the Java client. It then spawns a socket connection for each such client. In addition, a Guru search server [Maarek, 1991] is running, but is only accessed through the Java server process.
The Java client consists of the user interface just described and a single connection object to the server process which exchanges messages requesting server side actions such as "Search the context thesaurus," "Search the relationships graph," or "Search the Guru document index." Each such request causes the Java server to launch a different C program which actually implements the request. Each of these C programs returns its data to standard-out which is received by the Java server, formatted in a predefined manner, and sent back to the client. Search failures are handled by returning a specific blank string.
Talent Extraction Tools
The lower layer server processes which construct these indexes are built using the Talent extraction tools. These tools comprise a set of heuristic text analysis functions designed to extract and organize vocabularies and lexical networks from ordinary text using fast (usually finite-state) techniques. In order to obtain speed, the heuristics sacrifice accuracy with the result that they can sometimes miss good items or relationships and extract bad ones. However, we have adopted a number of strategies which keep such mistakes to a minimum and usually result in the overwhelmingly large proportion of extracted material being useful.
In the context of user interfaces to computer systems, such as the LexNav interface, we further expect that human users' semantic processing capability, combined with their knowledge of the application domain, will allow them to ignore small numbers of mistakes in Talent extracts, as being at least irrelevant and at most funny or mildly annoying. We have not studied this carefully but, at least anecdotally, our expectations have been borne out.
Talent vocabularies consist of "vocabulary items." Each item has a "canonical form" and zero or more "variant forms." Strictly speaking, the canonical form is also a variant and is sometimes called the "canonical variant." Depending on the item the canonical form is chosen because it is least ambiguous, the most explicit, the longest, the lemma, etc., among all the variants. Vocabulary items also have a category associated with them. The combination of canonical form and category are unique within a Talent vocabulary. Depending on the application, vocabulary items may also have collection statistics stored with them. Function words and many non-content stop words are excluded.
Nominator. Talent's name extraction tool is called Nominator [Wacholder, et al., 1997]. It finds single- and multi-word names using heuristics based mainly on capitalization patterns together with a large inventory of word patterns characteristic of proper names. Nominator can assign names to the categories Person, Place, Organization, Other (for names of laws, and other miscellany), and Uncat. An important aspect of its operation is that it can find multiple variant forms of names that occur in the same document. These variants can be long and short versions of person names ("John F. Kennedy" vs. "J. Kennedy"). Names can include or exclude empty words like "Corp.," "Senator," or "Esq." Acronym and abbreviations of fullforms occurring in the same document are included among the fullform's variants.
Terminator. Talent's technical term extraction tool, Terminator, finds multi-word technical terms [Justeson & Katz, 1995]. Terminator uses a heuristic based on the structure of technical terms: technical terms usually have a structure that is a subset of the noun phrases. The structure of terms in text is determined with a regular expression over the possible parts-of-speech of the word tokens in the text. No parsing or part-of-speech disambiguation is used. Variant forms of terms include case variations and forms in which one or more of the words are inflected. Canonical variants tend to be lower-case and to contain lemma forms. Terminator's heuristic also requires that a term be repeated in a document (at least once) in order to be recognized. This captures the notion that technical terms are things that documents can be "about." Arbitrary noun phrases that are never repeated in an entire document collection are probably not technical terms and are not included in Talent vocabularies.
Abbreviator. Talent's Abbreviator tool can recognize abbreviations and acronyms in a document and match them with their corresponding fullforms. Its recognizer contains a finite-state process, which identifies the local syntactic contexts in which abbreviations and acronyms typically occur. Identified contexts are submitted to a more detailed matching procedure which examines the candidate shortforms and fullforms that they contain. This procedure consists primarily of constraints on the matches between letters in the two candidate forms. Pairs which survive the matching filter are added to the vocabulary, with the fullform becoming the canonical form.
Aggregator. The initial vocabularies formed from the output of Nominator, Terminator, Abbreviator, and other extractors (not mentioned here) must be aggregated by Talent's Aggregator before they are useful. Duplicate vocabulary items found in multiple documents are eliminated. Near-duplicates must be examined to determine whether they can refer to the same concept; if so, they are merged. Resulting categories must be assigned to merged vocabulary items. For some applications, Aggregator computes occurrence statistics and stores them with the items. Aggregator's output is the Talent vocabulary.
Context Thesaurus. As already mentioned, the context thesaurus is a device which can produce a ranked list of vocabulary items related to a query. The context thesaurus's basic data structure is an IR index of a set of "pseudo-documents." There is one pseudo-document per vocabulary item, and that vocabulary item serves as its title. Each pseudo-document contains sentential contexts in which the vocabulary item occurs in the original document collection.
Talent constructs the context thesaurus in a three-step process. First, a concordance is constructed, listing all occurrences of every vocabulary item in the collection. Second, the set of sentential contexts for each vocabulary item, in turn, are inspected, filtered, and gathered into a pseudo-document. Third, the pseudo-documents are indexed with a standard IR system's indexer. In our prototype application, we used IBM Research’s Guru system. However, any system that can handle queries of the type we want to process and whose query engine can provide ranked document retrieval is suitable. Recently, we have utilized IBM’s NetQuestion server as well. Access to the resulting context thesaurus is simple. When any query is processed against the index of pseudo-documents, the hitlist produced is a list of ranked vocabulary items where the rank indicates the degree of relatedness between the item and the query.
Unnamed Relations. The notion behind unnamed relations is simple: vocabulary items which often appear together are likely to be related. Furthermore, the extent to which two items appear together can be used to measure the strength of the relationship between them.
Many implementations of the notions behind unnamed relations are possible. The current implementation uses the context thesaurus. For a pair of vocabulary items, the unnamed-relation process determines the extent to which one item occurs in the context of the other by querying the context thesaurus for each item. Recall that the context thesaurus assigns a rank to the items on a query's hitlist. When the query is a vocabulary item, the rank of a hitlist item can be interpreted as a numerical value of the strength of association between the query item and the hitlist item. If each item appears on the other item’s hitlist with a frequency that exceeds some threshold and if the ranks are fairly close, we assume that there is a symmetric relation between the two items. The strength of the relationship is computed to be the average of the two ranks from the two queries. In Guru, hitlist ranks are normalized values between 0 and 100. The unnamed relation process uses a rank of 50 as the threshold.
Unnamed relations are represented as triples of
<vocabulary-item::strength::vocabulary-item>
The context thesaurus itself also implicitly contains a set of asymmetric unnamed relations. When any vocabulary item is used as a query, the items on the context thesaurus hitlist are in a one-way relationship to the query item. The relationship between the two items is asymmetric unless the hitlist item, when used as a query, produces the original query item on its own context thesaurus hitlist, as described. For example, the relationship between "Alphonse Gratz" (who lives in New York State) and "New York State" is most likely asymmetric, whereas the relationship between "George Pataki" (governor of New York State) and "New York State" is probably symmetric. Of course the distinction between symmetric and asymmetric relations is a fluid one and depends on the text in the document collection.
Named Relations. Talent extracts named relations between vocabulary items by exploiting text patterns in which such relationships are typically expressed. These text patterns include appositive constructions, possessive constructions, parentheticals, short copular clauses, coordinate constructions, etc. As with many of the other Talent extractors, a set of finite state processes are used to identify the occurrences of text patterns of interest and then to analyze and filter the material in the patterns to extract relations.
The named relation extractor operates in "discovery mode." That is, it is not necessarily primed with specific relation names that it is looking for. Rather, the relation names, along with the participating vocabulary items are identified by virtue of the positions they occupy in the defining text patterns. This allows for the extraction of collection-specific relations.
Named relations are represented as triples of
<vocabulary-item::relation-name::vocabulary-item>.
and are inherently asymmetric.
Lexical Networks. Named and unnamed relations are combined to form the lexical networks used in LexNav. The triples constituting the relations are stored in an LGraph structure (see below).
In the current implementation, only symmetric unnamed relations are included in the networks. As mentioned, above, LexNav users have access to asymmetric relations through the context thesaurus. However, in the future this decision may be revised and some asymmetric relations may also be stored in lexical networks.
Talent Access Facilities
As described above, the upper layer LexNav server consists of a number of processes that support the various access commands issued by the client.
Guru. The search engine used for document retrieval is Guru. It should be noted that Guru itself does not know about or use Talent vocabulary items in its processing. Like many IR systems supporting free-text queries, however, it does exploit word proximity during query processing. The fact that queries enhanced with the vocabulary-based methods described in the paper show improved performance in Guru suggests that the enhancement methods are independent of the underlying query processing engine.
Context Thesaurus. Guru is used to access the context thesaurus, by processing context thesaurus queries against the pseudo-document index described above. Items from the top of the ranked hitlist are returned to the client.
LGraph. Named and unnamed relations, their strengths, and their directions are retrieved from the lexical networks stored in LGraph data structures. The LGraph access functions permit efficient access to connected subparts of large lexical networks. Typical access parameters are vocabulary items and/or relation names or relation strengths.
GLOW. GLOW ("Graph Layout or What!") is a visual tool for accessing graph structures, such as lexical networks, through a two-dimensional user interface. It consists of a client part, illustrated in Section 2, and a server part. The server uses LGraphs to access lexical network data and contains layout algorithms (based on the work described in [Tunkelang, 1994]) to compute two dimensional presentations of lexical networks for display at the client. The layout algorithms are incremental and thus support LexNav's navigation metaphor very well.
Performance and Scalability
One of the Talent project goals is for the extraction tools to operate quickly enough for use in real applications. The current lexical network construction process (specifically, the vocabulary, context thesaurus, and named relation extraction tools) operates at about 100 megabytes of text per hour, on an IBM PowerPC 604-based RS/6000 computer. The largest lexical navigation application to date has been for a 140-megabyte collection of financial and technology documents, heavily marked-up with HTML.
Lexical networks and context thesauruses can be constructed incrementally, so the increase in time required to process larger collections should be nearly linear with the size of the collections. As noted above, the LexNav server access functions consist of standard information retrieval engines and direct access methods. Their performance and scalability should also be standard for such technology.
5. Conclusions and Future Work
This work has allowed us to put a number of fairly complex technologies in front of inexperienced users and provides us both with a way to illustrate their effectiveness and a way to evaluate the users’ responses to specific interface representations. Our initial conclusions are that they quickly grasped the value of the context thesaurus and made effective use of it, and that they found the relationship information diverting but that we have not made it integral to the search process yet. However, the use of Java and a Web browser client to the search technology was generally deemed extremely successful.
Further work in this area certainly will involve a revision of the interface using Java 1.1 tools and controls, and tighter integration between context thesaurus, keywords and relationships. In addition, we plan to replace the Guru search engine with an industrial strength system such as IBM’s Search Manager. Since this revision will then allow Boolean queries, this will further affect the revision of the user interface.
Talent development continues on a number of fronts. We are experimenting with a number of new methods for extracting unnamed relations, including using data mining techniques to analyze concordances of vocabulary items. In cases where published thesauruses exist for domains being analyzed, it may be possible and advantageous to use them to enhance extracted lexical networks. We will continue to test the Talent tools on ever larger document collections and work on applications which combine multiple collections.
Acknowledgements
As in all efforts of this type, our success depends in part on the work of many other people. We are particularly grateful to our colleagues in the Digital Libraries department at IBM Research. They include Mary Neff, who designed and built Terminator, Yael Ravin and Misook Choi, who designed and built Nominator, Herb Chong and Aaron Kershenbaum, who originated many of our dictionary subsystems, Daniel Tunkelang, who designed and built GLOW, Lucy Nowell and Birgit Schmidt-Wesche, who made a number of usability suggestions, and Alan Marwick, who inspired us to turn our ideas into a working system. None of them, of course, bears any responsibility for errors we may have made in describing their technology and using it in LexNav.
Bibliography
| Arnold, Ken and Gosling, James, The Java Programming Language, Addison-Wesley, 1996. |
| Bates, Marcia J. "Human, Database, and Domain Factors in Content Indexing and Access to Digital Libraries and the Internet," Allerton, 1996. |
| Brajnik, G., S. Mizzaro, and C. Tasso "Evaluating User Interfaces to Information Retrieval Systems: A Case Study on User Support" in Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 128-136. |
| Buckley, C., Singhal, A., Mira, M & Salton, G. (1996) "New Retrieval Approaches Using SMART:TREC4. In Harman, D, editor, Proceesings of the TREC 4 Conference, National Institue of Standards and Technology Special Publication. |
| Byrd, R. J., Y. Ravin, and J. Prager "Lexical Assistance at the Information-Retrieval User Interface," Proceedings of the SDAIR (Symposium on Data Analysis and Information Retrieval), UNLV, 1995. |
| Church, K. W. "One Term or Two?" in Proceedings of the 18th Annual ACM-SIGIR Conference, 1995, pp 310-318. |
| Cooper, James W., The Visual Basic Programmer’s Guide to Java, Ventana, 1996. |
| Furnas, G. W., T, K., Landauer, L. M. Gomez, and S. T. Dumais "The Vocabulary Problem in Human-System Communication" in Communications of the ACM, vol. 30, no. 11, November 1987, pp. 964-971. |
| Harman D. "Relevance Feedback and Other Query Modification Techniques", in W. B. Frakes and R. Baeza-Yates, eds., Information Retrieval: Data Structures and Algorithms, Prentice-Hall, 1992. |
| Hearst, Marti A. and Pedersen, Jan O., "Reexamining the Cluster Hypothesis: Scatter/Gather on Retrieval Results." Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 76-84. |
| Hendry, David G. and Harper, David J., "An Architecture for Implementing Extensible Information Seeking Environments," Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 94-100. |
| Jing, Y. and W. B. Croft "An association thesaurus for information retrieval", in Proceedings of RIAO 94, 1994, pp. 146-160. |
| Justeson, J. S. and S. Katz "Technical terminology: some linguistic properties and an algorithm for identification in text." Natural Language Engineering, 1, 9-27, 1995. |
| Lesk, M. "Automatic Sense Disambiguation using Machine-Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone", in Proceedings of the 1986 SIGDOC conference, 1986. |
| Maarek, Y.S., "Software Library Construction from an IR perspective," in SIGIR Forum, fall 1991, 25:2, 8-18. |
| NIST 1993. TIPSTER Information-Retrieval Test Research Collection, on CD-ROM, published by The National Institute of Standards and Technology, Gaithersburg, MD. |
| Nowell, Lucy Terry, France, Robert K, Hix, Deborah, Heath, Lenwood S., and Fox, Edward A. "Visualizing Search Results: Some Alternatives to Query-Document Similarity." Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 67-75. |
| Ravin Y. "Disambiguating Proper Names in Text", in Proceedings of MIDDIM 96, International Seminar on Multimodal Interactive Disambiguation, Col de Porte, August 1996. |
| Ravin Y. and N. Wacholder. 1996, "Extracting Names from Natural-Language Text," IBM Research Report 20338. |
| Schatz, Bruce R, Johnson, Eric H, Cochrane, Pauline A and Chen, Hsinchun, "Interactive Term Suggestion for Users of Digital Libraries." ACM Digital Library Conference, 1996. |
| Spink A, A. Goodrum, D. Robins, and M. M. Wu "Elicitations During Information Retrieval: Implications for IR System Design" in Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 120-127. |
| Spink, A. "Term Relevance Feedback and Query Expansion: Relation to Design" in Proceedings of the 17th Annual ACM-SIGIR Conference, 1994, pp. 81-90. |
| Srinivasan, P. "Thesaurus Construction", in W. B. Frakes and R. Baeza-Yates, eds., Information Retrieval: Data Structures and Algorithms, Prentice-Hall, 1992. |
| Tunkelang, D. D. "A Practical Approach to Drawing Undirected Graphs", Technical Report CMU-CS-94-161, Carnegie Mellon University, June 1994. |
| Voorhees, E. M. "Query Expansion using Lexical-Semantic Relations" in Proceedings of the 17th Annual ACM-SIGIR Conference, 1994, pp. 61-69. |
| Wacholder, N., Ravin, Y., and Choi, M. "Disambiguation of Proper Names in Text," Proceedings of the Fifth Conference on Applied Natural Language Processing, 1997. |
| Xu, Jinxi and Croft, W. Bruce. "Query Expansion Using Local and Global Document Analysis," Proceedings of the 19th Annual ACM-SIGIR Conference, 1996, pp. 4-11 |